クローラーとは?検索エンジンが巡回する仕組みを解説

「クローラー」という言葉をよく耳にすることはありますが、具体的な仕組みやその役割など知らない方や間違えた解釈をしている方も多いんじゃないでしょうか?本記事ではSEO対策でもよく用いられる「クローラー」について詳しく解説します。
クローラーとは
「クローラー」とは、インターネット上の情報を自動的に集め、データベース化するプログラムのことです。這い回るという意味の【crawl】から名称されており、「ボット」や「スパイダー」などとも呼ばれることもあります。
クローラーは、WEBサイトやWEBページの情報を収集するために使用されます。
具体的には、クローラーがWEBサイトのリンクをたどって新しいURLを発見します。ページの情報を取得して、取得した情報は、検索エンジンのデータベースに保存されインデックスされます。
ここまでを自動でおこなうプログラムの総称がクローラーになります。
このようにクローラーが自動でWEBサイトを巡回し、WEBサイトのデータを収集する検索エンジンを「ロボット型検索エンジン」と言います。
日本でロボット型検索エンジンで利用者が最も多いのは、Google検索エンジンです。
そのため、日本でクローラーと言えば一般的には「Googleのクローラー」を指します。
Googleのクローラーとは
Googleのクローラーは、Googlebotと呼ばれています。
Googlebotは、検索結果に表示させるWebページの情報を収集するために、Webサイトを定期的に巡回して、Webサイトの「HTML」「CSS」「JavaScript」などのコードを解析し、ページ上のテキスト、画像、リンク、メタデータなどを取得します。
GooglebotはWebサイトの情報を取得する際に、様々な技術を使用しています。
例えば、
- Webページのコンテンツやサイトの構造を分析して、ページのテーマや内容を判断する
- ページの表示速度や表示のズレ・構造化データの使用・重複コンテンツを判断する
など、Googlebotはこのような詳細な情報を取得することができるため、ユーザーが検索した際に膨大なデータから最適なページを選別し、最も検索クエリと関連性が高いぺ―ジを検索結果に表示させることができます。
また、Googleから公開されているクローラーはGooglebot以外にも「画像用:Googlebot-Image」「ニュース用・Googlebot-News」等、収集する対象に応じて複数のクローラーをGoogleは用意しています。
クローラーの種類
クローラーはそれぞれの検索エンジンごとに開発・運用をおこなっているため、Google以外にもクローラーの種類は複数あります。
▼ Google以外のクローラーは以下になります。
- Bingbot(マイクロソフト社の検索エンジンBing)
- Baiduspider(百度)
- Yahoo Slurp(日本以外のYahoo!)
- Yetibot(Naver)
- ManifoldCF(Apache)
- AppleBot(Apple)
検索エンジンごとにクローラーもそれぞれありますが、YahooもGoogleの検索エンジンを使っていることもあり、Googleの検索エンジンが世界一です。
日本のシェアも80%以上あることから、クローラーに対する対策に関しては、Googlebot向けであることがほとんどです。
クローラーの取得対象となるファイル
Googleのクローラーが取得するファイルはHTMLのファイルだけではありません。
検索結果に表示されることが多くなった動画、画像なども取得対象となっています。
クローラが実際に読み取るファイルの一覧は以下になります。
・HTML
クロールの統計情報レポート - Google Search Console ヘルプ
・画像 (Google で取得可能な画像ファイル形式BMP、GIF、JPEG、PNG、WebP、SVG )
・動画 (Google で取得可能な動画ファイル形式: 3GP、3G2、ASF、AVI、DivX、M2V、M3U、M3U8、M4V、MKV、MOV、MP4、MPEG、OGV、QVT、RAM、RM、VOB、WebM、WMV、XAP)
・JavaScript
・CSS
・その他の XML - XML をベースとした RSS、KML などの形式を含まない XML ファイル
・JSON
・シンジケーション - RSS フィードまたは Atom フィード
・音声
・地理データ - KML または他の地理データ。
・その他のファイル形式 - ここに記載されていないその他のファイル形式。
・不明(失敗) - リクエストが失敗した場合、ファイル形式は不明となります。
このように、HTML以外にも多くの情報をクローラーは取得しています。
動画や画像などもクローリングしてもらいたい場合は、ファイル形式を間違えないように記述しましょう。
クローラーの仕組み
クローラーは、インターネット上にある膨大な数のWEBページをリンクを辿って巡回し、自動で新しいURLを発見します。
発見されたURLはクローラーによって解析され、ページの内容にガイドライン違反やnoindexの記述が無ければ、Googleのデータベースに登録をおこない検索結果に表示させます。
クローラーがサイトを巡回しなければ検索結果にインデックスされることはありません。
そのため、クローラーの仕組みを理解することはWEBサイトを運用する上で重要です。
次の項目でクローラーがインデックスするまでの仕組みを詳しく解説します。
Googleクローラーがインデックスするまでの流れ
Googleクローラーが、WEBサイトやぺージを発見してからインデックスするまでにどのような過程があるのか説明します。
クローラーがインデックスするまでの基本的な順序は、
- URLの発見
- クロールキュー(検出)
- クロール
- レンダリング
- インデックス
です。
それぞれ詳しく説明します。
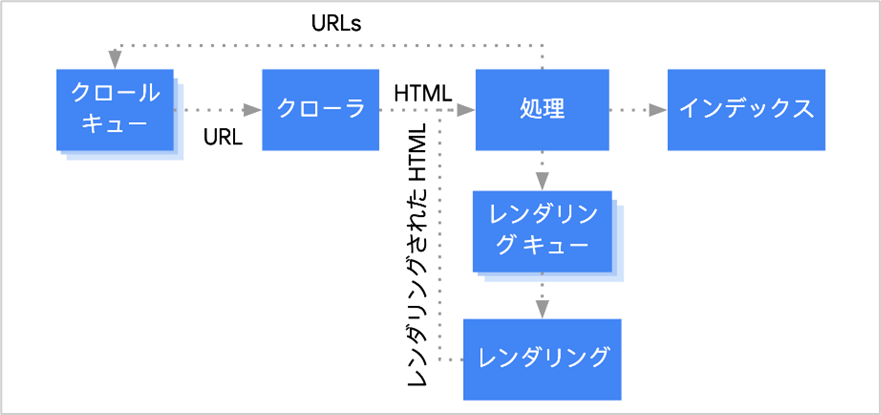
URLの発見
クローラーがWEBサイト上の「内部リンク」「外部リンク」を辿り、新しいURLを検出します。その際に「href属性」に記述されたURLを読み込み、データベースに存在していないURLがあるか無いかを判断します。
内部リンク・外部リンク以外にも、サーチコンソールの「URL検査」から申請されたインデックス登録リクエストや「XMLサイトマップ」を送信することでURLを検出します。
クロールキュー(検出)
クローラーが新しいURLを発見すると、発見したURLをクロール待ちのリストに追加します。
これをクロールキューと言います。
クローラーはクロールキューに追加されたURLの中から、優先度が高いURLから順にクロールをおこないます。
ページ数が100,000を超えるような大規模サイトの場合などは、全てのページをクロールできない可能性があるため、優先的にクロールしてもらいたいページにクローラーが巡回するように調整する必要があります。
クロール
クロールの項目では、Googlebotは主に以下2つの動作をおこないます。
- robots.txtでクロールが許可されているかの確認
- href属性を検出し新しいURLをクロールキューに追加する
具体的に説明します。
クロールキューからクロールに移行した際に一番最初に、robots.txtファイルを読み込んでGooglebotのクロールが許可されているかどうかを確認します。
robots.txt内のdisallowでGooglebotのクロールが許可されていない場合は、クロールをせずに別のURLのクロールに進みます。
クロールが許可されている場合、Googlebotは次にHTML内から、「href属性」から始まる他ページのURLを検出しクロールキューに追加します。
この時にクローラーに他ページのURLを検出させないようにするにはnofollowタグを使用します。
レンダリング
レンダリングの項目では主に以下の動作をおこないます。
- noindexタグが設定されているかどうかの確認
- htmlを分析してCSSやJavaScriptをブラウザでの表示内容に変換します。
具体的に説明します。
クロール後に、Googlebotはnoindexタグによりページのインデックスを拒否していないかどうかを確認します。
インデックスが許可されている場合、ページのソースコードを読み取りHTML・CSSを構築して「実際にユーザーが見るブラウザ上の画面での表示内容に変換し、問題が無いか確認します。」
これをレンダリングと言います。
レンダリングされたページがGooglebotからどのように見えているかは、サーチコンソールの「URL検索」からライブテストをおこなうことで確認できます。
インデックス
クロール・レンダリングの順序を経て、検索エンジンのデータベースにWEBページが保存されて、ようやく検索結果に表示されるようになります。検索エンジンのデータベースに保存されることを「インデックス」されると言います。
インデックス登録時に、titleタグやhタグ・altタグの読み込みやテキストの読み込みをおこないます。
また、重複ページ・正規ページの確認作業を得て問題が無い場合、インデックス登録され検索結果に表示されます。
クローラーが新しいURLを発見する方法
せっかくページを作成しても、クローラーに認識されなければインデックス化されないため、検索結果に表示されることもありません。
では、クローラーは新しいURLをどのように発見しているのかご説明します。
内部リンクと外部リンクを辿る
クローラーは、ページ内の内部リンクと外部リンクを辿って新しいURLを発見します。
具体的には、Googlebotがページをクロ―リングする際に「href属性」に記述されたURLを読み込み、データベースに存在していないURLがあるか無いかを判断します。
そのため、サイト内に新しいURLを追加した場合は、既にクロール対象となっているURLからの内部リンクを設置することで、クローラーに新しいURLを発見してもらうことができます。
ただし、クローラーが内部リンクもしくは、外部リンクを設置したページを巡回しないと新しいURLを発見できないため、いつ発見して貰うことができるのかはGoogle次第となります。
「URL検査ツール」からインデックス登録リクエストをされた場合
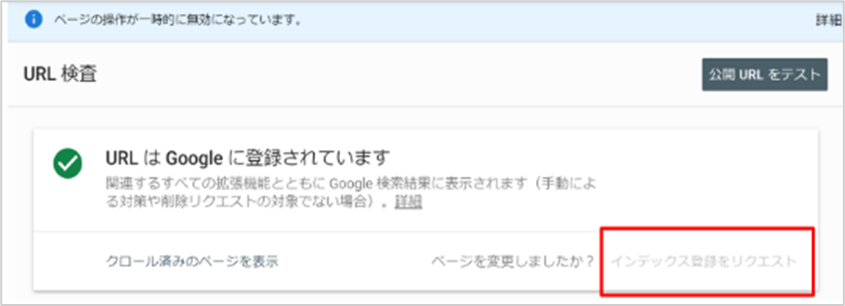
サーチコンソールの「URL検査ツール」から「インデックス登録リクエスト」をおこなうことでクローラーは新しいURLを発見することができます。
URL検査ツールはURLのインデックス状況を確認するツールですが、インデックス登録をリクエストされた場合、GooglebotはリクエストされたURLをクローキューに追加し、クロール・インデックスをおこなう準備をします。
この過程で新しいURLを発見します。
新しくサイトを立ち上げた場合や、新たにぺージ追加したが既存のページからの内部リンクが無い場合などは、この方法を使ってクローラーに新しいURLを発見してもらいましょう。
▼ URL検索ツールの使い方は別記事にて詳しく解説しています。
XMLサイトマップに新しいURLの記述がある場合
XMLサイトマップを送信することで、サイトの構造やサイト内のURLをクローラーに伝えることができます。
そのため、XMLサイトマップに新しいURLが記述されている場合、クローラーは新しいURLを発見することができます。
XMLサイトマップに新しいURLを記述していない場合は、サーチコンソールからXMLサイトマップを送信して新しいURLは発見して貰えません。
URL検査は個別にURLを送信する必要がありますが、XMLサイトマップであれば一括で複数のURLを送信することができるため、新規でサイトを立ち上げた場合や、リニューアルで新しいページを大量に作った場合はこちらの方法を利用しましょう。
▼ XMLサイトマップについては別記事で詳しく解説しています。
クローラーが巡回したページを確認する方法
クローラーが巡回したページを確認するには、サーチコンソールを使って確認する必要があります。
サーチコンソールを使うことで、巡回したページの情報以外にも「いつクロールしたのか」「クロールした結果どのように処理されたのか」など、クロールについて詳細なデータを知ることができます。
それでは、サーチコンソールを使ってクローラーが巡回したページを確認する方法を紹介します。
Googleサーチコンソールの「URL検査」で確認する
「URL検索ツール」は指定したURLをクローラーが巡回したかどうかを確認することができます。
▼ 確認手順は以下になります。
- サーチコンソールにログイン
- メニューから「URL検索」をクリック
- 上部の検索窓に確認したいURLを入力
- 画面上に表示された「ページのインデックス登録」をクリック
- 展開されるのでステータスを確認する。
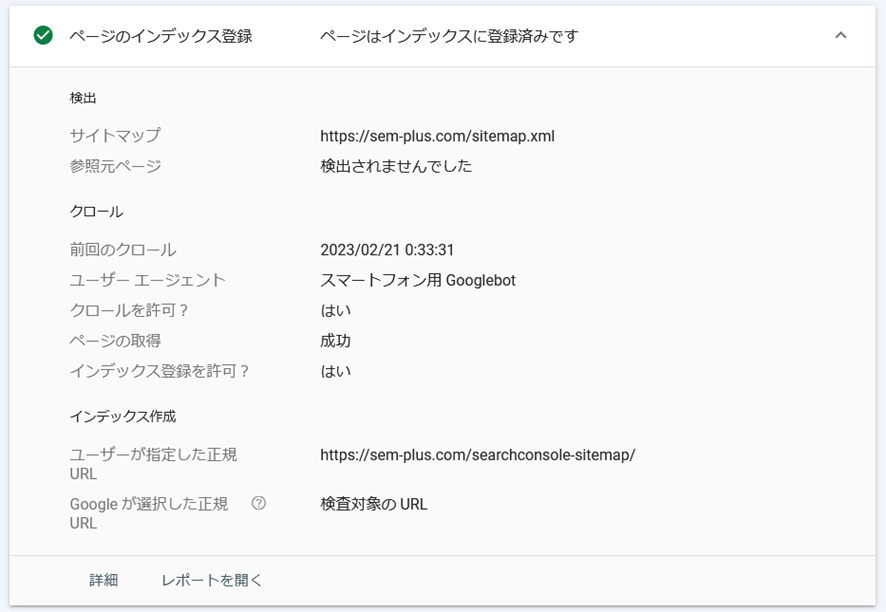
ステータスを確認することで、クローラーが巡回した日付や参照元となったURLを確認することができます。
Googleサーチコンソールの「インデックス作成」を確認する
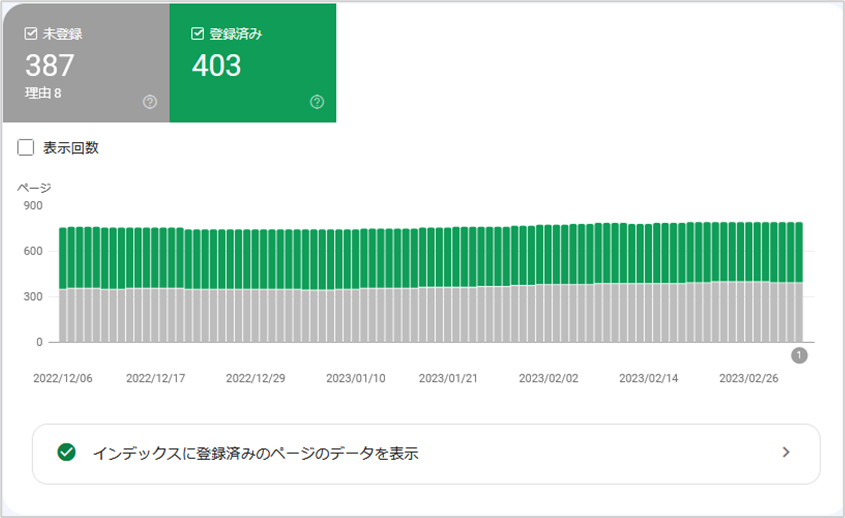
「インデックス作成レポ―ト」は本来、インデックスの状況を確認する項目ですが、「インデックスされている=クローラーが巡回している」となるため、このレポ―トからもクローラーが巡回したページを確認することができます。
▼ 手順は以下になります。
- メニューからインデックス作成をクリック
- 「インデックスに登録済みのページのデータを表示」をクリックするとクロール・インデックス済みのURLを確認できます。
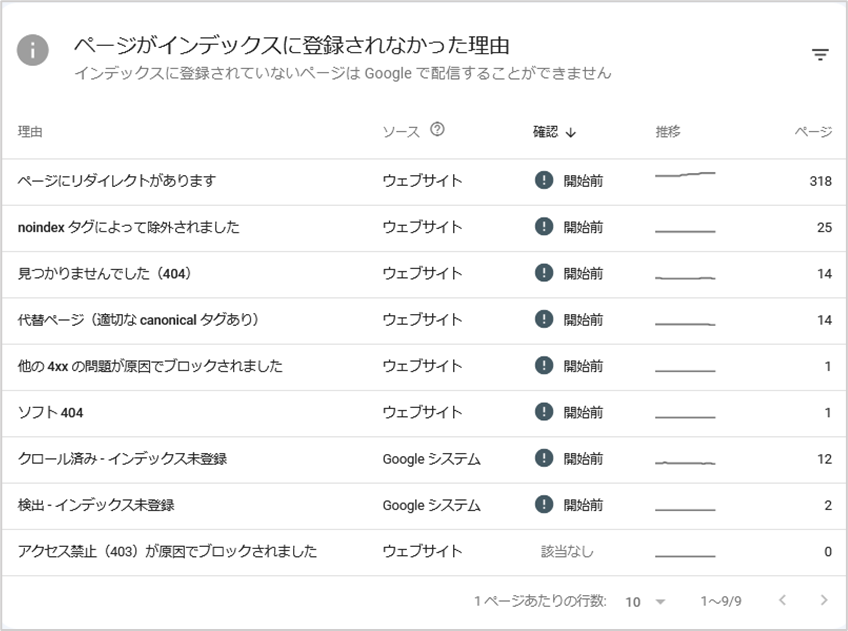
「ページがインデックスに登録されなかった理由」に表示されている項目に関しても、クロ―ラ―は巡回していますが、何らかの理由でインデックスされなかったURLとなります。
ただし、「検出 - インデックス未登録」に表示されたURLはクロールされていないURLです。
クローラーにサイトをクローリングさせない方法
robots.txtを使用する
robots.txt を使用することで、検索エンジンのクローラーからのアクセスを制御することができます。例えば、Googlebotからのクローリングだけを拒否したり、特定のURLのクローリングを拒否することができます。
▼ robots.txtでクローラーを拒否する書き方は以下になります。
- User-agent:Googlebot
- Disallow:/〇〇〇/
User-Agentには、拒否したいクローラーの記載をします。
Googlebotを拒否したい場合は上記のように記述します。「*(アスタリスク)」を記述すると全てのクローラーを拒否します。
Disallowにクロ―ラ―を拒否したいディレクトリ名を「〇〇〇」の部分に指定します。
※「/」だけを記述するとWEBサイト内の全てのURLを拒否します。
※指定したディレクトリ以下の全てのURLでクロ―ラ―を拒否します。
.htaccessを使用する
ページにパスワードをかけた場合、クローラーはページの中にアクセスすることができないため、ページ内をクロ―リングすることが出来ません。
具体的には、「.htaccess」を使いページをパスワードで保護することでクローリングを防ぎます。
パスワードでページを保護した場合、パスワードを知らないクローラーはページにアクセスすることができません。
そのため、Googlebotがぺージをクローリングすることができずインデックスを防ぐことができます。当然、パスワードを知らないユーザーにも、ページの中身を見られることはありません。
.htaccessでパスワードをかける方法が、クローラーにページ内容を読み込ませない方法として一番確実な方法となります。
パスワード制限をかける場合は、パスワードをかけたいディレクトリに「.htaccess」と「.htpassword」という2つのファイルを作成してアップロードします。
■「.htpassword」作成方法
.htaccessファイルには、以下4桁の内容を記述します。
| AuthType |
| Basic AuthName “認証画面に表示されるメッセージ (例:(IDとパスワードを入力してください))” |
| AuthUserFile /home/ドメイン名/フォルダ名/.htpasswd |
| require valid-user |
■「.htpassword」作成方法
| ユーザー名:パスワード |
| ユーザー名2:パスワード2 |
■作成したファイルのアップロード先
.htaccessと.htpasswordの2つのファイルをサーバーにアップロードします。
これで設定は完了です。
リンク先のクローリングを拒否する場合はnofollowを使う
内部リンクや外部リンクを設置した際に、リンク先のページのクロ―リングを拒否する場合は、nofollowタグを利用します。
nofollowタグは「href属性」で指定したリンク先をクロールさせない命令文のため、nofollowタグに記述されたURLをクローラーは巡回しません。
リンク先のサイトと自分のサイトを関連付けたくない場合や、リンクジュースを渡しくない場合などに使用します。
▼ nofollowについては別記事で詳しく解説しています。
クロール頻度を高めるための方法
そもそもクロール頻度とはどのような意味なのか?
2つの意味があり、クロール巡回頻度とクロール速度があります。
1. クロール巡回頻度
Googleのクローラーがサイトにやってくる頻度で、一般的にクロール頻度の意味合いはこちらになります。クロール頻度はGoogleがサイトごとに自動的に決定するため、クローラーの巡回頻度はURLによって大きく異なります。
2. クロール速度
クロール速度とは、Googlebotがクロールする際にリクエストを送信する1秒あたりの回数です。Googleサーチコンソールで使われる意味で、クロール頻度設定ページで設定ができるようになっています。
クローラーの巡回頻度は、サイト側から指定することはできませんが高める方法はあります。
本章では、クロールの巡回頻度を高めるための方法についてご説明します。
低品質なぺージを削除・リライトする
低品質なページが多いサイトはクローラーの巡回頻度が低下します。
低品質なページとは「他社のページと類似している」「内容が薄く専門的ではない」「広告のバナーが多い」などユーザーにとって役に立たない可能性が高いぺ―ジを指します。
このような価値の低いページが多い場合は、サイト全体のクロール頻度の低下に繋がります。
低品質なぺージに該当する場合は、ページのリライトや削除をおこないサイト全体の品質を高めましょう。
重複コンテンツを削除する
重複コンテンツとは、サイト内のぺージ同士で内容が重複しているコンテンツのことです。
例えば、自社サイト内に似たような内容のページが存在したり、URLの正規化がされておらず、同一の内容のページが複数存在したりすると、重複コンテンツと判断される可能性があります。
当然、重複コンテンツとみなされると低品質のサイトと判断されてクロール巡回頻度が少なくなります。さらにクロール巡回頻度が悪くなるだけでなく、ペナルティの対象になる場合もあるので注意が必要です。
URLの正規化をおこなう
URLを正規化されていない場合は、クロ―ル対象のURLが多くなるためクローラーの巡回頻度が低下する可能性があります。
URLの正規化とは、同じ内容のページで「http,httpsが存在する」「wwwの有無が存在する」「index.htmlの有無が存在する」場合に1つのURLに統合することを指します。
URLの正規化をおこなうことでクロール対象となるページが少なくなり、Googleが評価するページも正規化されたURLの1つとなるためSEO効果も高まります。
URLの正規化が出来ていない場合は、重複ページと判断される可能性もあるため、正規化をまだおこなっていない場合は早急に対応しましょう。
▼ URLの正規化については別の記事で詳しく解説しているのでご確認ください。
リンクが切れているページを削除する
リンク切れが多く発生してるサイトの場合、クロール頻度が低下する可能性があります。
クローラーはページをクロ―リングするたびに、リンクを辿って新しいURLを探すため、リンク切れが多い場合は、巡回効率が悪くなってしまいます。
リンク切れが多くある場合は、クロール頻度だけでなくユーザビリティの低下にも繋がるため改善をおこないましょう。
リンク切れを確認するには無料で使えるリンクチェッカーを使うと手間なく確認することができます。
robots.txtで不要なページへのクロールをブロックする
robots.txtは検索エンジンのクローラーに対して巡回して良いURLかどうかの許可を出すことができるので、インデックスさせる必要が無いページに関してはrobots.txtでクロールをブロックします。ブロックすることで、クローラーの巡回が必要なページだけに制御することができます。
10万ページを超える大規模なサイトの場合は、全てのページがクロールされる訳ではないため、不要なページへのクロールを制御して重要なぺ―ジへのクロール頻度を高めましょう。
サーバーの応答速度を高める
契約しているサーバーのプランが低く、高負荷に対応していない場合クロールの巡回頻度が低下する可能性があります。
Googleはクロールにより、サーバーに負荷をかけていると判断した場合は敢えてクロール頻度を下げることがあります。
この場合、サーバーのプランを上げるなどしてサーバーを強化することで、サーバーの応答速度が高まり改善されます。
サーバーに負荷がかかっている場合は、クロール頻度を制限することもできますが新しいページがインデックスされる速度も遅くなるため、基本的にはサーバーを強化して対応しましょう。
クロールの頻度を制御する方法
クロール頻度を調整しないといけないケースがあります。サイト運営者は基本的にクロール頻度を高めるようと試行錯誤しますが、クロール頻度が増加することで、Googleのクロールによるアクセスが原因でサーバーに負荷がかかることがあります。
その際は、クロールの頻度を制御してサーバーへの負荷を軽減する必要があります。クロール頻度の調節は、サーチコンソールから設定することが可能です。
次の項目で詳しく解説します。
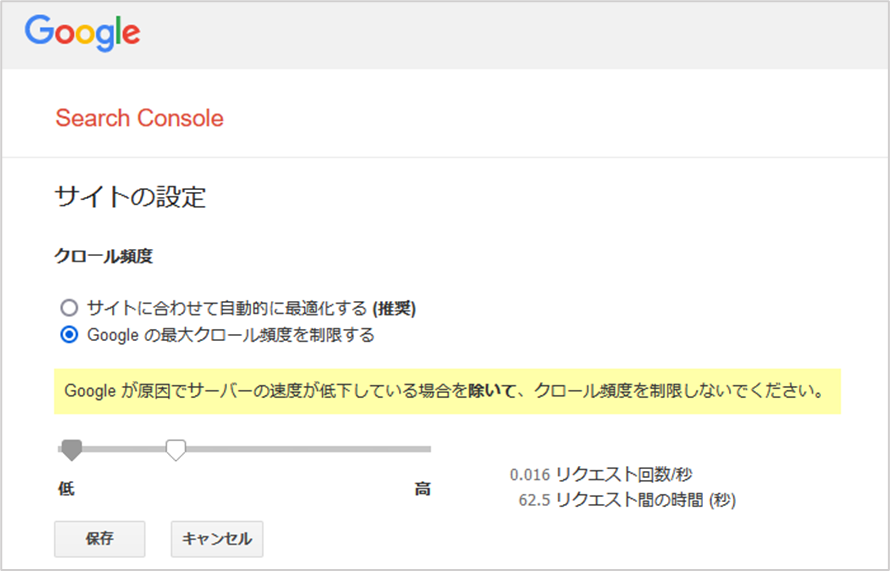
Googleサーチコンソールから設定をおこなう
クロール頻度を制御する際はGoogleサーチコンソールのから申請を行うことができます。
手順としては、
- プロパティのクロール頻度設定ページをページを開く
- デフォルトの設定では「Googleが最適化を行う設定」となっている
- 「Googleの最大クロール頻度を制限する」にチェックする。
新たに設定したクロール頻度は、数日以内に反映されて90日間有効です。
注意点としては、このページからクロール頻度の調整をする場合、クロール頻度を減らすことはできても、クロールの頻度を増やすことはできません。
何か理由があってクロール頻度を減らしたい場合にのみ利用しましょう。
クローラーについてよくあるご質問
クローラーについてよくある質問をまとめました。
クローラビリティを高めるためには?
クローラビリティを高めるには以下の方法をおこないます。
- XMLサイトマップの申請
- 内部リンクの設定をおこなう
- URLの正規化をおこなう
- 重複ページを削除する
- 低品質なコンテンツを削除する
- 不要なページはrobots.txtでクローラーを拒否する
ページがなかなかクロールされない場合の原因とは?
クロールされない原因は複数あります。原因の見つけ方は以下の手順でおこないます。
まずは、robots.txtや.htaccessでクローラーを拒否する設定がされていないかの確認をします。
クローラーを拒否していない場合、Googleサーチコンソールの「URL検査」から原因を確認します。
クローリングされないとどうなりますか?
クローラーが発見したURLに対してページの情報が取得されないので、WEBサイトが検索エンジンに登録されません。その結果、インデックスはされないので検索結果に表示されません。
まとめ
今回は、クローラーについて解説しました。クローラーによるページの巡回がされなければ、インデックスされずページが検索結果に表示されません。
クローラーの仕組みと役割を正しく理解することで、インデックスがされない原因と改善策を考えることができるようになるため、クローラーについて知ることはサイトを運営する上では重要な意味を持ちます。
特にSEO対策をおこなう場合や、大規模サイトを運用する場合は、クロールをコントロールする必要があるため、本記事でしっかりとクローラーについて覚えておくようにしましょう。

この記事を書いたライター

SEO施策部
SEMを軸にSEOの施策を行うオルグロー内の一部署。 サイト構築段階からのSEO要件のチェックやコンテンツ作成やサイト設計までを一貫して行う。社内でもひときわ豊富な知見を有する。またSEO歴15年超のノウハウをSEOサービスに反映し、3,000社を超える個人事業主から中堅企業までの幅広い顧客層に向けてビジネス規模にあった施策を提供し続けている。
RECOMMENDED ARTICLES
ぜひ、読んで欲しい記事














